
代码拉取完成,页面将自动刷新
同步操作将从 gohouse/gorose 强制同步,此操作会覆盖自 Fork 仓库以来所做的任何修改,且无法恢复!!!
确定后同步将在后台操作,完成时将刷新页面,请耐心等待。




_______ ______ .______ ______ _______. _______
/ _____| / __ \ | _ \ / __ \ / || ____|
| | __ | | | | | |_) | | | | | | (----`| |__
| | |_ | | | | | | / | | | | \ \ | __|
| |__| | | `--' | | |\ \----.| `--' | .----) | | |____
\______| \______/ | _| `._____| \______/ |_______/ |_______|
gorose是一个golang orm框架, 借鉴自laravel的eloquent.
gorose 2.0 采用模块化架构, 通过interface的api通信,严格的上层依赖下层.每一个模块都可以拆卸, 甚至可以自定义为自己喜欢的样子.
模块关系图如下: 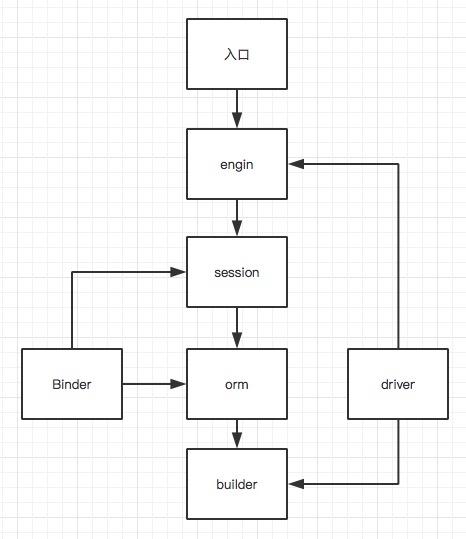
require github.com/gohouse/gorose v2.0-rc10
docker run -it --rm ababy/gorose sh -c "go run main.go"
docker 镜像: ababy/gorose, docker镜像包含了gorose所必须的包和运行环境, 查看
Dockerfile
db.Table().Fields().Where().GroupBy().Having().OrderBy().Limit().Select()
db.Table().Data().Insert()
db.Table().Data().Where().Update()
db.Table().Where().Delete()
gorose提供数据对象绑定(map, struct), 同时支持字符串表名和map数据返回. 提供了很大的灵活性
建议优先采用数据绑定的方式来完成查询操作, 做到数据源类型可控
gorose提供了默认的 gorose.Map 和 gorose.Data 类型, 用来方便初始化绑定和data
简单配置
var configSimple = &gorose.Config{
Driver: "sqlite3",
Dsn: "./db.sqlite",
}
更多配置, 可以配置集群,甚至可以同时配置不同数据库在一个集群中, 数据库会随机选择集群的数据库来完成对应的读写操作, 其中master是写库, slave是读库, 需要自己做好主从复制, 这里只负责读写
var config = &gorose.ConfigCluster{
Master: []&gorose.Config{}{configSimple}
Slave: []&gorose.Config{}{configSimple}
Prefix: "pre_",
Driver: "sqlite3",
}
初始化使用
var engin *gorose.Engin
engin, err := Open(config)
if err != nil {
panic(err.Error())
}
创建用户表 users
DROP TABLE IF EXISTS "users";
CREATE TABLE "users" (
"uid" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
"name" TEXT NOT NULL,
"age" integer NOT NULL
);
INSERT INTO "users" VALUES (1, 'gorose', 18);
INSERT INTO "users" VALUES (2, 'goroom', 18);
INSERT INTO "users" VALUES (3, 'fizzday', 18);
定义表struct
type Users struct {
Uid int `gorose:"uid"`
Name string `gorose:"name"`
Age int `gorose:"age"`
}
// 设置表名, 如果没有设置, 默认使用struct的名字
func (u *Users) TableName() string {
return "users"
}
原生查询操作
// 这里是要绑定的结构体对象
// 如果你没有定义结构体, 则可以直接使用map, map示例
// var u = gorose.Data{}
// var u = gorose.Map{} 这两个都是可以的
var u Users
session := engin.NewSession()
// 这里Bind()是为了存放结果的, 如果你使用的是NewOrm()初始化,则可以直接使用 NewOrm().Table().Query()
err := session.Bind(&u).Query("select * from users where uid=? limit 2", 1)
fmt.Println(err)
fmt.Println(u)
fmt.Println(session.LastSql())
原生增删改操作
session.Bind(&u).Query("insert into users(name,age) values(?,?)(?,?)", "gorose",18,"fizzday",19)
session.Bind(&u).Query("update users set name=? where uid=?","gorose",1)
session.Bind(&u).Query("delete from users where uid=?", 1)
var u Users
db := engin.NewOrm()
err := db.Table(&u).Fields("name").AddFields("uid","age").Distinct().Where("uid",">",0).OrWhere("age",18).
Group("age").Having("age>1").OrderBy("uid desc").Limit(10).Offset(1).Select()
type user gorose.Map
// 或者 以下的type定义, 都是可以正常解析的
type user2 map[string]interface{}
type users3 []user
type users4 []map[string]string
type users5 []gorose.Map
type users6 []gorose.Data
db.Table(&user).Select()
db.Table(&users4).Limit(5).Select()
注意: 如果使用的不是slice数据结构, 则只能获取到一条数据
这里使用的 gorose.Data , 实际上就是 map[string]interface{} 类型.
而 gorose.Map, 实际上是 t.MapString 类型, 这里出现了一个 t 包, 是一个golang基本数据类型的相互转换包, 请看详细介绍 http://github.com/gohouse/t
First(),Get(), 用来返回结果集[]gorose.Map结果集, 第二个是error,看成简单粗暴Select() 方法换成 Get,First 即可, 只不过, Select() 只返回一个参数db.Table(&user2).Limit(10.Select()
db.Table(&user2).Where("uid", 1).Data(gorose.Data{"name","gorose"}).Update()
db.Table(&user2).Data(gorose.Data{"name","gorose33"}).Insert()
db.Table(&user2).Data([]gorose.Data{{"name","gorose33"},"name","gorose44"}).Insert()
db.Table(&user2).Where("uid", 1).Delete()
目前支持 mysql, sqlite3, postgres, oracle, mssql, clickhouse等符合 database/sql 接口支持的数据库驱动
这一部分, 用户基本无感知, 分理出来, 主要是为了开发者可以自由添加和修改相关驱动以达到个性化的需求
这一部分也是用户无感知的, 主要是传入的绑定对象解析和数据绑定, 同样是为了开发者个性化定制而独立出来的
gorose2.0 完全模块化, 每一个模块都封装了interface接口api, 模块间调用, 都是通过接口, 上层依赖下层
database/sql包的接口以上主模块, 都相对独立, 可以个性化定制和替换, 只要实现相应模块的接口即可.
sql
DROP TABLE IF EXISTS "users";
CREATE TABLE "users" (
"uid" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
"name" TEXT NOT NULL,
"age" integer NOT NULL
);
INSERT INTO "users" VALUES (1, 'gorose', 18);
INSERT INTO "users" VALUES (2, 'goroom', 18);
INSERT INTO "users" VALUES (3, 'fizzday', 18);
实战代码
package main
import (
"fmt"
"github.com/gohouse/gorose"
_ "github.com/mattn/go-sqlite3"
)
type Users struct {
Uid int64 `gorose:"uid"`
Name string `gorose:"name"`
Age int64 `gorose:"age"`
Xxx interface{} `gorose:"-"` // 这个字段在orm中会忽略
}
func (u *Users) TableName() string {
return "users"
}
var err error
var engin *gorose.Engin
func init() {
// 全局初始化数据库,并复用
// 这里的engin需要全局保存,可以用全局变量,也可以用单例
// 配置&gorose.Config{}是单一数据库配置
// 如果配置读写分离集群,则使用&gorose.ConfigCluster{}
engin, err = gorose.Open(&gorose.Config{Driver: "sqlite3", Dsn: "./db.sqlite"})
}
func DB() gorose.IOrm {
return engin.NewOrm()
}
func main() {
// 这里定义一个变量db, 是为了复用db对象, 可以在最后使用 db.LastSql() 获取最后执行的sql
// 如果不复用 db, 而是直接使用 DB(), 则会新建一个orm对象, 每一次都是全新的对象
// 所以复用 db, 一定要在当前会话周期内
db := DB()
// 查询一条
var u Users
// 查询数据并绑定到 user{} 上
err = db.Table(&u).Fields("uid,name,age").Where("age",">",0).OrderBy("uid desc").Select()
if err!=nil {
fmt.Println(err)
}
fmt.Println(u, u.Name)
fmt.Println(db.LastSql())
// 查询多条
// 查询数据并绑定到 []Users 上, 这里复用了 db 及上下文条件参数
// 如果不想复用,则可以使用DB()就会开启全新会话,或者使用db.Reset()
// db.Reset()只会清除上下文参数干扰,不会更换链接,DB()则会更换链接
var u2 []Users
err = db.Limit(10).Offset(1).Select()
fmt.Println(u2)
// 统计数据
var count int64
// 这里reset清除上边查询的参数干扰, 可以统计所有数据, 如果不清楚, 则条件为上边查询的条件
// 同时, 可以新调用 DB(), 也不会产生干扰
count,err = db.Reset().Count()
// 或
count, err = DB().Table(&u).Count()
fmt.Println(count, err)
}
Chunk 数据分片 大量数据批量处理 (累积处理)
当需要操作大量数据的时候, 一次性取出再操作, 不太合理, 就可以使用chunk方法 chunk的第一个参数是指定一次操作的数据量, 根据业务量, 取100条或者1000条都可以 chunk的第二个参数是一个回调方法, 用于书写正常的数据处理逻辑 目的是做到, 无感知处理大量数据 实现原理是, 每一次操作, 自动记录当前的操作位置, 下一次重复取数据的时候, 从当前位置开始取
User := db.Table("users")
User.Fields("id, name").Where("id",">",2).Chunk(2, func(data []map[string]interface{}) {
// for _,item := range data {
// fmt.Println(item)
// }
fmt.Println(data)
})
// 打印结果:
// map[id:3 name:gorose]
// map[id:4 name:fizzday]
// map[id:5 name:fizz3]
// map[id:6 name:gohouse]
[map[id:3 name:gorose] map[name:fizzday id:4]]
[map[id:5 name:fizz3] map[id:6 name:gohouse]]
Loop 数据分片 大量数据批量处理 (从头处理)
类似 chunk 方法, 实现原理是, 每一次操作, 都是从头开始取数据 原因: 当我们更改数据时, 更改的结果可能作为where条件会影响我们取数据的结果,所以, 可以使用Loop
User := db.Table("users")
User.Fields("id, name").Where("id",">",2).Loop(2, func(data []map[string]interface{}) {
// for _,item := range data {
// fmt.Println(item)
// }
// 这里执行update / delete 等操作
})
嵌套where
// SELECT * FROM users
// WHERE id > 1
// and ( name = 'fizz'
// or ( name = 'fizz2'
// and ( name = 'fizz3' or website like 'fizzday%')
// )
// )
// and job = 'it' LIMIT 1
User := db.Table("users")
User.Where("id", ">", 1).Where(func() {
User.Where("name", "fizz").OrWhere(func() {
User.Where("name", "fizz2").Where(func() {
User.Where("name", "fizz3").OrWhere("website", "like", "fizzday%")
})
})
}).Where("job", "it").First()
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。